در حال حاضر محصولی در سبد خرید شما وجود ندارد.
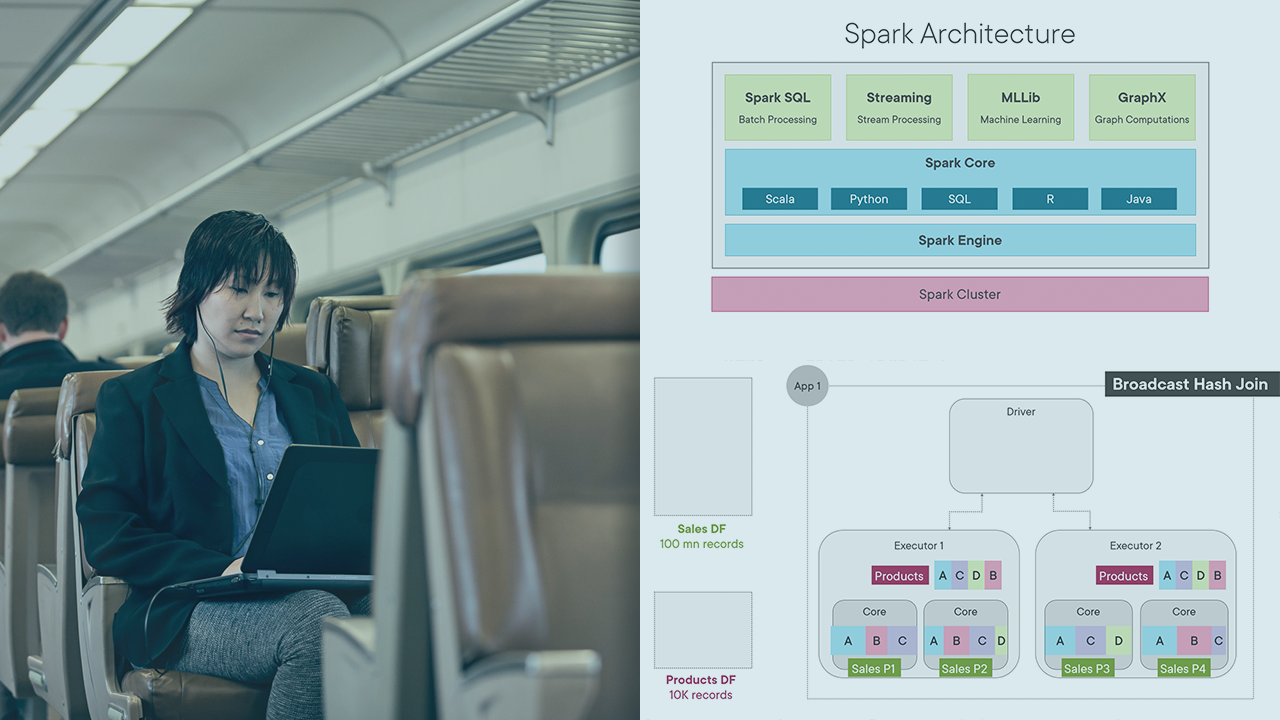
Learn the Fundamentals of Apache Spark 3: process data, set up the environment, use RDDs & DataFrames, optimize apps, build pipelines with Databricks and Azure Synapse. Familiarize yourself with Spark's ecosystem here in this course.
در این روش نیاز به افزودن محصول به سبد خرید و تکمیل اطلاعات نیست و شما پس از وارد کردن ایمیل خود و طی کردن مراحل پرداخت لینک های دریافت محصولات را در ایمیل خود دریافت خواهید کرد.


آموزش ساخت یک Data Lakehouse بوسیله Azure Synapse Analytics

Data Literacy: Essentials of Azure Synapse Analytics

Querying Data with Snowflake

Moving Data with Snowflake

انتقال داده ها با Snowflake

Microsoft Fabric Analytics Engineer: Prepare and Serve Data

آموزش مفهوم سازی و پروسه ها در Azure Databricks Service

سواد داده ها : یادگیری مبانی Azure Synapse Analytics

Building Your First Data Lakehouse Using Azure Synapse Analytics

فیلم یادگیری Handling Streaming Data with Azure Databricks Using Spark Structured Streaming

فوری … نیمی از محصولات حذف شد! حذف کامل سایت تا اواسط تیر توضیحات