در حال حاضر محصولی در سبد خرید شما وجود ندارد.
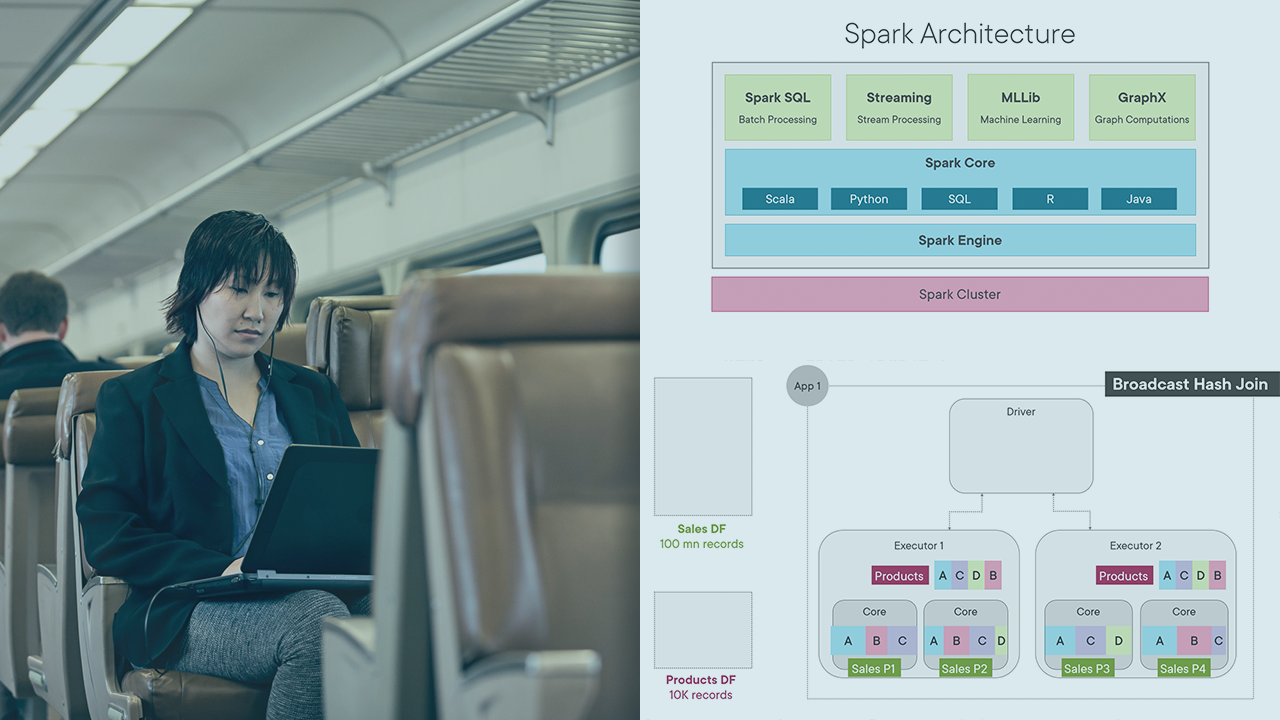
Learn the Fundamentals of Apache Spark 3: process data, set up the environment, use RDDs & DataFrames, optimize apps, build pipelines with Databricks and Azure Synapse. Familiarize yourself with Spark's ecosystem here in this course.
در این روش نیاز به افزودن محصول به سبد خرید و تکمیل اطلاعات نیست و شما پس از وارد کردن ایمیل خود و طی کردن مراحل پرداخت لینک های دریافت محصولات را در ایمیل خود دریافت خواهید کرد.


آموزش ساخت یک Data Lakehouse بوسیله Azure Synapse Analytics

Microsoft Fabric Analytics Engineer: Prepare and Serve Data

Querying Data with Snowflake

آموزش ساخت ETL Pipeline با استفاده از Azure Databricks

Moving Data with Snowflake

Building Your First Data Lakehouse Using Azure Synapse Analytics

فیلم یادگیری Handling Streaming Data with Azure Databricks Using Spark Structured Streaming

آموزش مفهوم سازی و پروسه ها در Azure Databricks Service

سواد داده ها : یادگیری مبانی Azure Synapse Analytics

انتقال داده ها با Snowflake

✨ تا ۷۰% تخفیف با شارژ کیف پول 🎁
مشاهده پلن ها