جمع جزء: 189,000 تومان
- × 1 عدد: Mastering Sustainable Success through Carbon Trading - 189,000 تومان
یکی از روشهای موفق یادگیری ماشینی Reinforcement Learning است. در این دوره آموزشی کدنویسی و کار با Reinforcement Learning ر در زبان برنامه نویسی Python به خوبی یاد می گیرید.
عنوان اصلی : Reinforcement Learning with Python Explained for Beginners
معرفی دوره و مدرس:
معرفی دوره و مدرس
یادگیری تقویت انگیزه:
یادگیری تقویتی چیست؟
Reinforcement Learning Hiders and Seekers توسط OpenAI چیست؟
RL در مقابل سایر چارچوب های ML
چرا یادگیری تقویتی
نمونه هایی از یادگیری تقویتی
محدودیت های یادگیری تقویتی
تمرینات
اصطلاحات یادگیری تقویتی:
محیط زیست چیست
Environment_2 چیست
عامل چیست
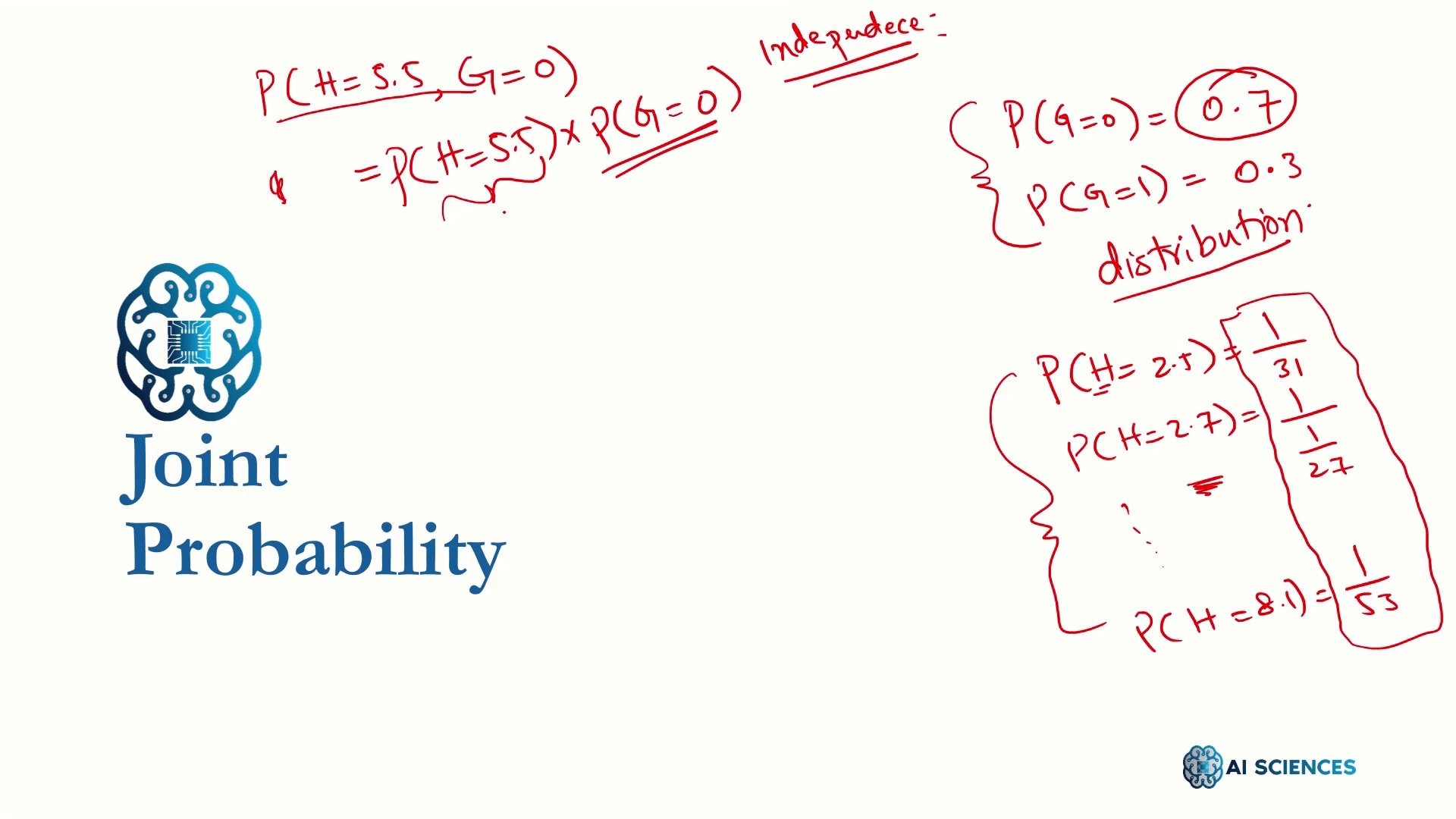
ایالت چیست
ایالت متعلق به محیط زیست است و نه به عامل
اکشن چیست
پاداش چیست
هدف
خط مشی
خلاصه
مثال GridWorld:
راه اندازی 1
راه اندازی 2
راه اندازی 3
مقایسه سیاست
محیط قطعی
محیط تصادفی
محیط تصادفی 2
محیط تصادفی 3
محیط غیر ساکن
خلاصه GridWorld
فعالیت
پیش نیازهای فرآیند تصمیم گیری مارکوف:
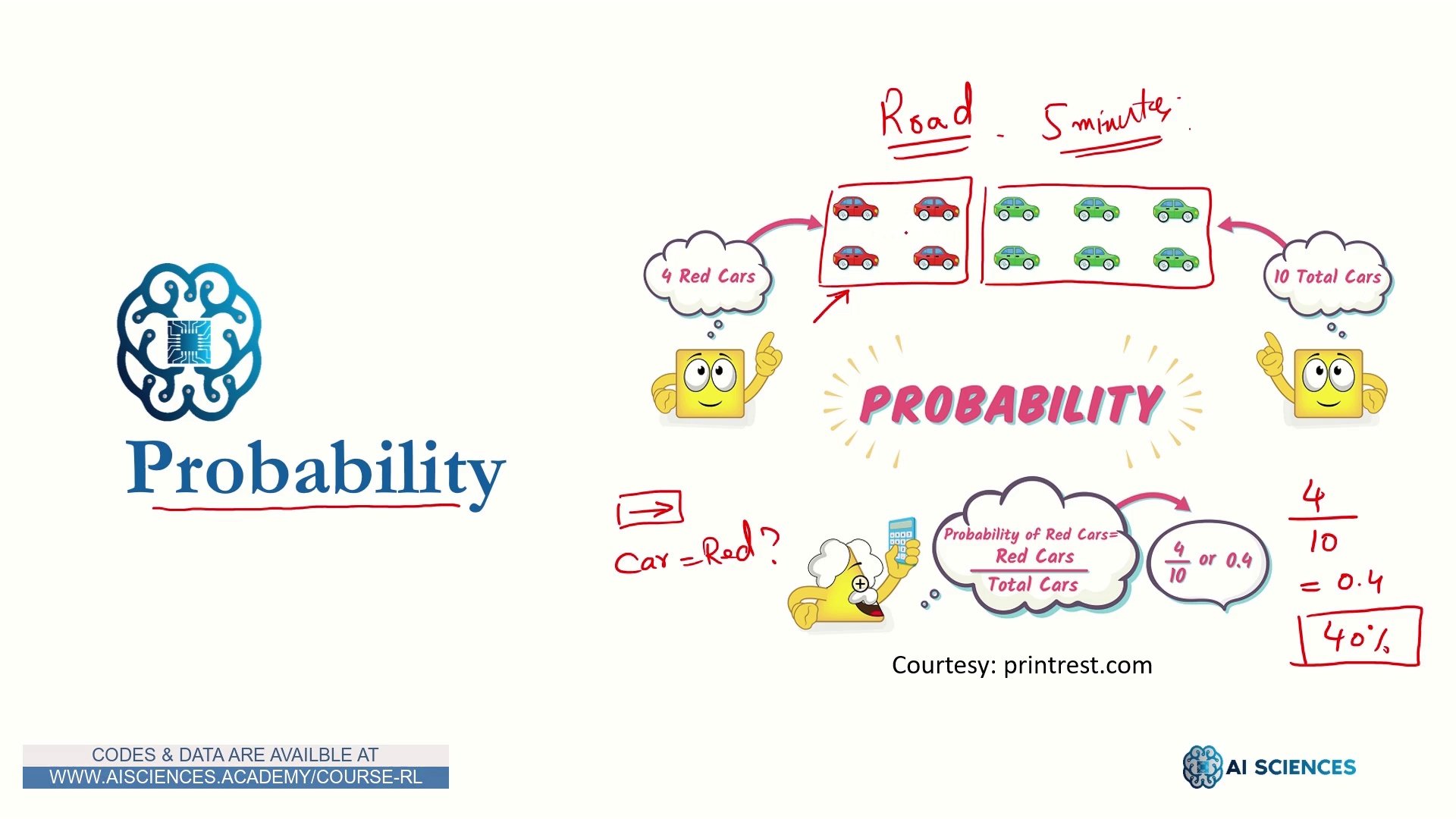
احتمال
احتمال 2
احتمال 3
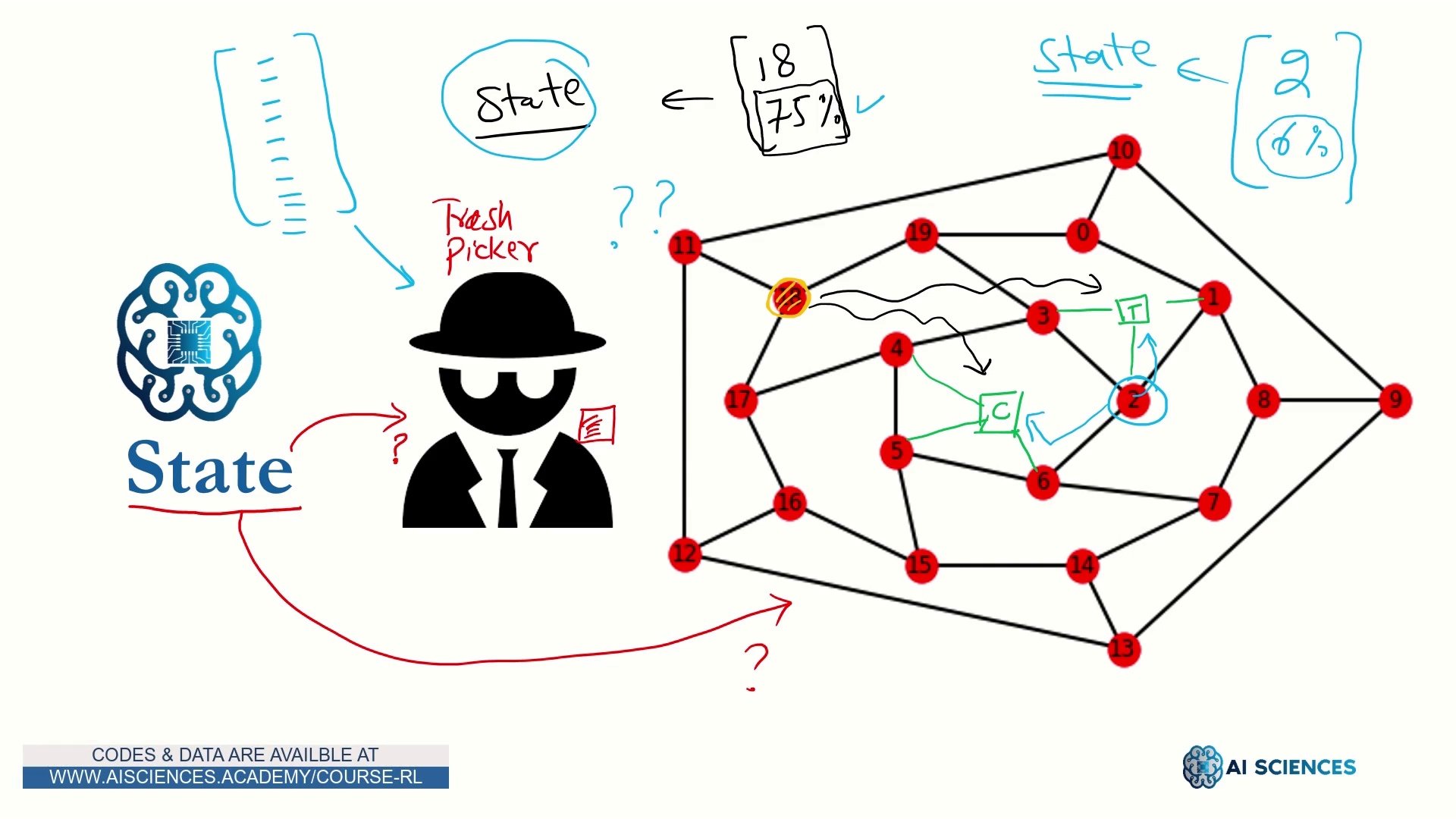
احتمال شرطی
مثال سرگرمی احتمال شرطی
احتمال مشترک
احتمال مشترک 2
احتمال مشترک 3
ارزش مورد انتظار
انتظار مشروط
مدلسازی عدم قطعیت محیط
مدلسازی عدم قطعیت محیط 2
مدلسازی عدم قطعیت محیط 3
مدلسازی عدم قطعیت سیاست تصادفی محیطی
مدلسازی عدم قطعیت سیاست تصادفی محیطی 2
مدلسازی عدم قطعیت توابع ارزش محیطی
میانگین های در حال اجرا
میانگین های در حال اجرا 2
در حال اجرا میانگین ها به عنوان تفاوت زمانی
فعالیت
عناصر فرآیند تصمیم گیری مارکوف:
دارایی مارکوف
فضای ایالتی
فضای اکشن
احتمالات انتقال
تابع پاداش
عامل تخفیف
خلاصه
فعالیت
اطلاعات بیشتر در مورد پاداش:
آزمون MOR 1
راه حل آزمون MOR 1
مسابقه MOR 2
راه حل آزمون MOR 2
مقیاس بندی پاداش MOR
افق بی نهایت MOR
آزمون MOR 3
راه حل آزمون MOR 3
حل DP مارکوف:
خلاصه MDP
توابع ارزش
تابع ارزش بهینه
سیاست بهینه
معادله بلمن
تکرار ارزش
آزمون تکرار ارزش
آزمون گامای تکرار ارزش وجود ندارد
راه حل تکرار ارزش
مشکلات تکرار ارزش
ارزیابی خط مشی
ارزیابی خط مشی 2
ارزیابی خط مشی 3
ارزیابی خط مشی د فرم راه حل
تکرار خط مشی
ارزش های اقدام دولت
مقایسه V و Q
تقریب ارزش:
ناشناخته بودن MDP به چه معناست
چرا احتمالات انتقال مهم هستند
راه حل های مبتنی بر مدل
راه حل های بدون مدل
آموزش مونت کارلو
مثال یادگیری مونت کارلو
محدودیت های یادگیری مونت کارلو
تفاوت زمانی - یادگیری Q:
میانگین در حال اجرا
میزان یادگیری
معادله یادگیری
الگوریتم TD
اکتشاف در مقابل بهره برداری
سیاست حریص اپسیلون
سارسا
Q-Learning
اجرای Q-Learning برای MAPROVER Clipped
TD Lambda:
N-Step Look a Head
فرمولاسیون
ارزش های
TD Q-Learning TD Lambda
TD Q-Learning TD Lambda TD(Lambda) MAPRover Activity
Project Frozenlake (Open AI Gym):
دریاچه یخ زده 1
پیاده سازی Frozenlake
Reinforcement Learning with Python Explained for Beginners
در این روش نیاز به افزودن محصول به سبد خرید و تکمیل اطلاعات نیست و شما پس از وارد کردن ایمیل خود و طی کردن مراحل پرداخت لینک های دریافت محصولات را در ایمیل خود دریافت خواهید کرد.


Python Mastery for Data, Statistics & Statistical Modeling

Mastering Github: A Comprehensive Guide

Deep Learning: Python Deep Learning Masterclass

پردازش زبان طبیعی NLP در پایتون برای مبتدیان

Tableau Essentials: From Foundations to Visualization Master

AWS Mastery: Basics to Real-World AWS Projects Unleashed
یادگیری ماشین A-Z: پشتیبانی از دستگاه بردار با پایتون

MongoDB Mastery: Your Essential Guide to Dominating Database

کورس یادگیری احتمالات و آمار در زبان Python

Deep Learning: Python Deep Learning Masterclass

✨ تا ۷۰% تخفیف با شارژ کیف پول 🎁
مشاهده پلن ها







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}