در حال حاضر محصولی در سبد خرید شما وجود ندارد.

این دوره به شما آموزش خواهد داد که چگونه از انتزاع جرقه برای جریان داده ها استفاده کنید و تحولات را در جریان داده ها با استفاده از API های جریان ساختاری جرقه در Databricks Azure انجام دهید.
آنچه که شما یاد می گیرید
جریان ساخت یافته در Apache Spark، داده های زمان واقعی را به عنوان یک جدول که به طور مداوم اضافه شده است، رفتار می کند. این منجر به یک مدل پردازش جریان می شود که از همان API ها به عنوان یک مدل پردازش دسته ای استفاده می کند - این امر موجب می شود تا عملیات دسته ای ما برای کار بر روی جریان حرکت کند. بار پردازش جریان از کاربر به سیستم تغییر می کند، و آن را بسیار آسان و بصری برای پردازش جریان داده ها با جرقه.
در این دوره، پردازش داده های جریان با آپاچی جرقه در Databricks، شما یاد خواهید گرفت به جریان و داده های فرآیند با استفاده از انتزاعی ارائه شده توسط جریان جرقه ساختاری. اول، شما تفاوت بین پردازش دسته ای و پردازش جریان را درک می کنید و مدل های مختلفی را که می توانید برای پردازش داده های جریان استفاده کنید، ببینید. شما همچنین ساختار و پیکربندی API های جریان ساختاری جرقه را کشف خواهید کرد.
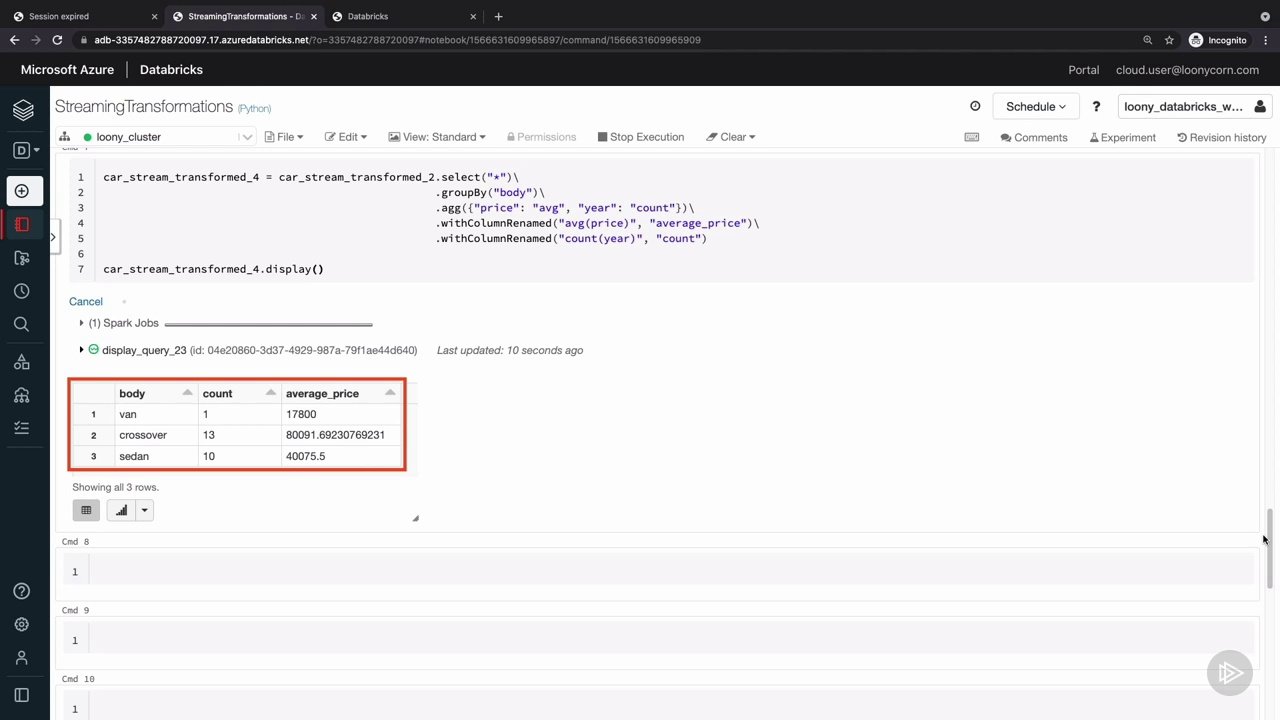
بعد، شما خواهید آموخت که چگونه از یک منبع جریان با استفاده از لودر خودکار در Databricks Azure بخوانید. لودر خودکار فرآیند خواندن داده های جریان را از یک سیستم فایل خودکار می کند و از مدیریت فایل ها و ردیابی فایل های پردازش شده مراقبت می کند و داده ها را از منابع ذخیره سازی ابر خارج می کند. پس از آن، تحولات و جمع آوری داده ها را در جریان داده ها انجام خواهید داد و داده ها را به ذخیره سازی با استفاده از مدل های اضافه، کامل و به روز رسانی ارسال کنید.
در نهایت، شما خواهید آموخت که چگونه از انتزاع SQL مانند در جریان های ورودی استفاده کنید. شما به یک منبع ذخیره سازی ابر خارجی، یک سطل آمازون S3 متصل خواهید شد و با استفاده از لودر خودکار در جریان خود بخوانید. پس از آن SQL Queries را برای پردازش داده های خود اجرا خواهید کرد. در طول راه، پردازش جریان خود را به صورت انعطاف پذیری با استفاده از بازرسی انجام می دهید و همچنین عملیات پردازش جریان خود را به عنوان یک کار بر روی یک خوشه شغلی databricks اجرا خواهید کرد.
هنگامی که شما با این دوره به پایان رسید، شما باید داشته باشید مهارت ها و دانش جریان داده ها در جرقه مورد نیاز برای پردازش و نظارت بر جریان ها و شناسایی موارد استفاده از موارد برای تحولات در جریان داده ها.
عنوان اصلی : Processing Streaming Data with Apache Spark on Databricks
سرفصل های دوره :
مرور دوره
پیش نیازها و طرح درس
پردازش دسته ای در مقابل پردازش جریان
پردازش میکرو و پردازش مداوم
جریان جریان در Apache Spark
برنامه های مداوم در جرقه
نسخه ی نمایشی: خواندن دسته دسته ای و جریان داده ها
نسخه ی نمایشی: اجرای یک پرس و جو ساده جریان
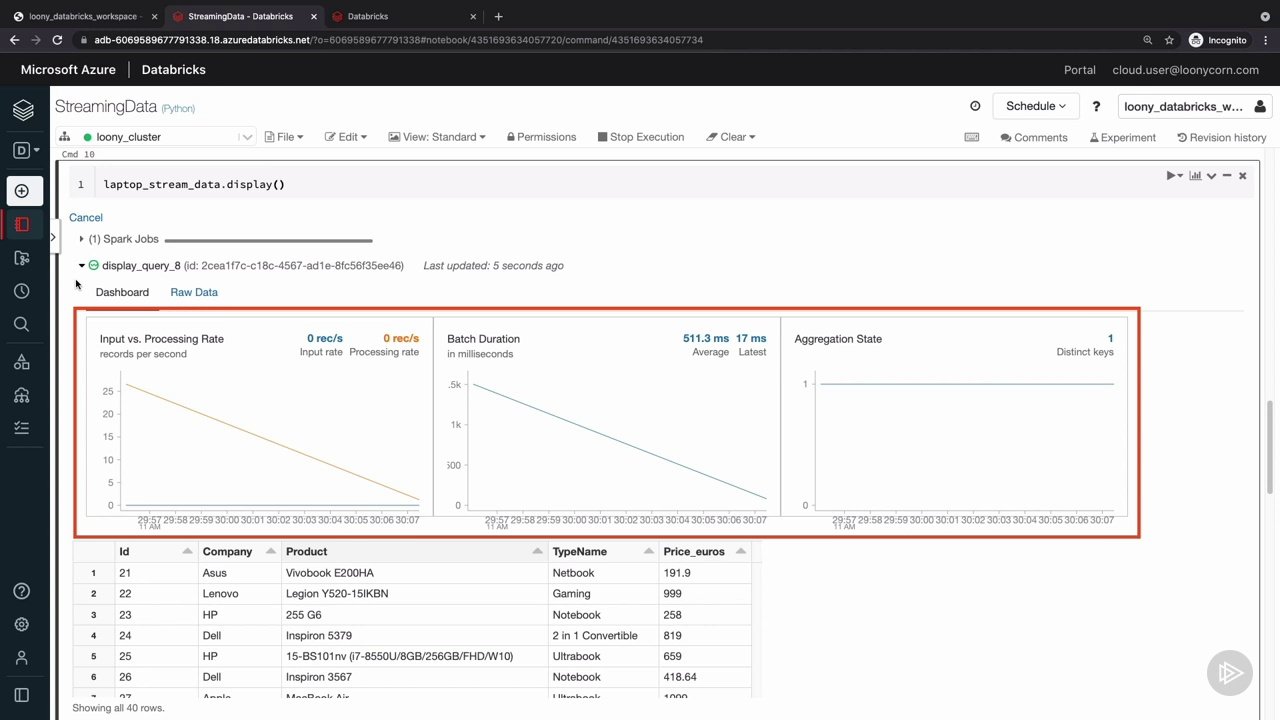
نسخه ی نمایشی: جریان پردازش و تجسم
triggers
نسخه ی نمایشی: پیکربندی Triggers
خلاصه ماژول
منابع جریان و غرق شدن
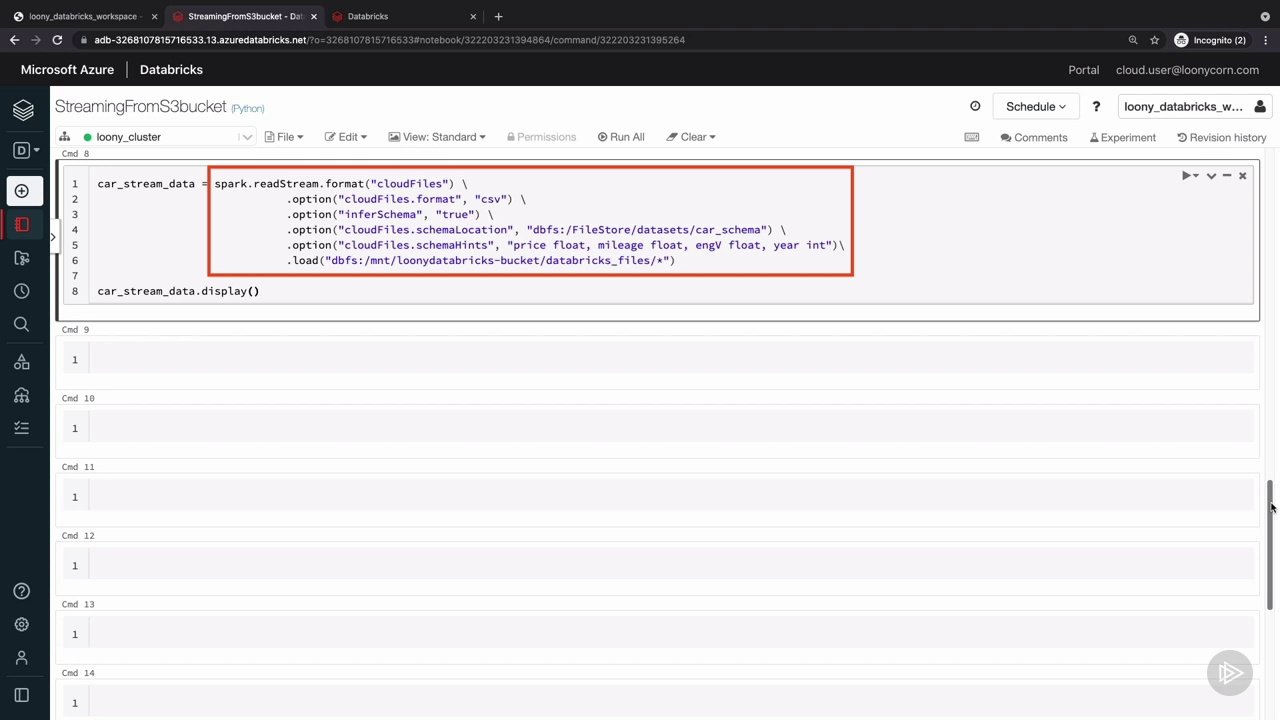
لودر خودکار
نسخه ی نمایشی: لودر خودکار و داده های نجات یافته
نسخه ی نمایشی؛ نوشتن جریان به فایل غرق
نسخه ی نمایشی: انجام تحولات در جریان ها
نسخه ی نمایشی: جریان جریان
حالت خروجی
نسخه ی نمایشی: حالت Append
نسخه ی نمایشی: حالت کامل
نسخه ی نمایشی: حالت به روز رسانی
نسخه ی نمایشی: اجرای SQL Queries به جریان جریان
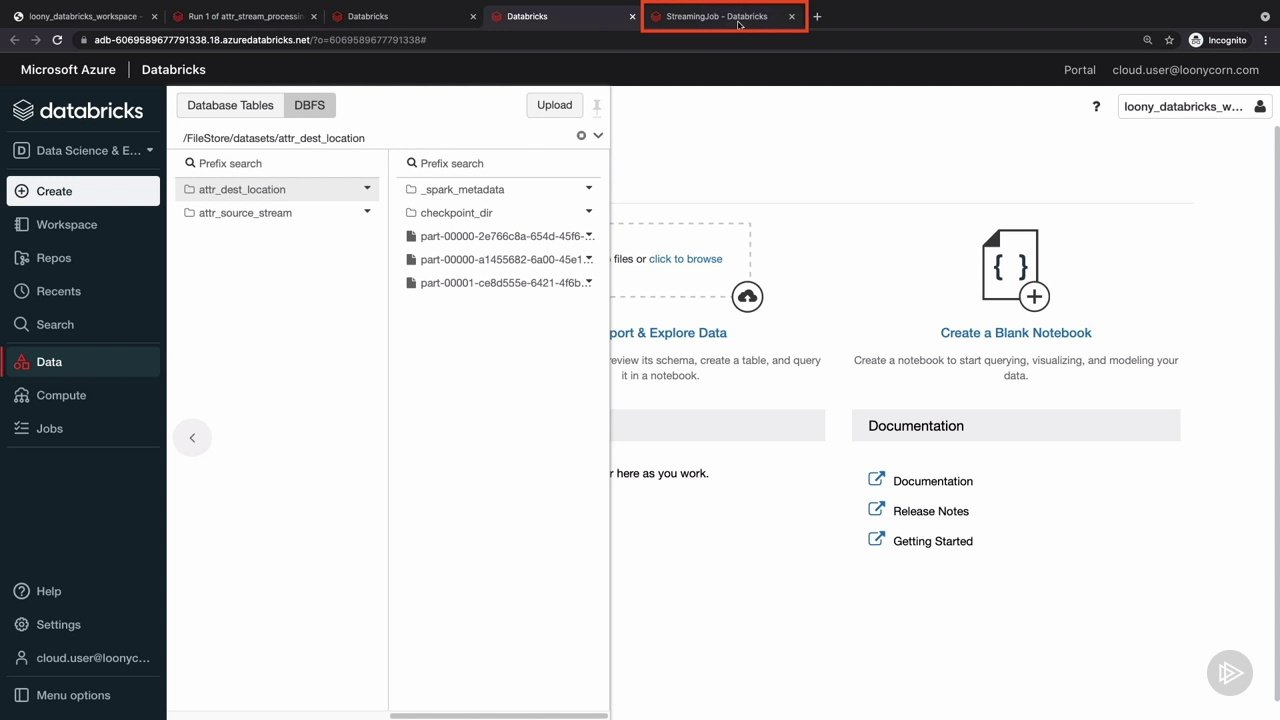
نسخه ی نمایشی: ایجاد یک کاربر AWS و S3 سطل
نسخه ی نمایشی: نصب یک سطل S3 به DBFS
نسخه ی نمایشی: لودر خودکار برای خواندن از یک منبع سطل S3
نسخه ی نمایشی: استفاده از UDFS در جریان داده ها
بازرسی
نسخه ی نمایشی: بازرسی
نسخه ی نمایشی: اجرای یک کار جریان در یک خوشه
نسخه ی نمایشی: مشاهده نتایج شغلی
خلاصه و مطالعه بیشتر
Processing Streaming Data with Apache Spark on Databricks
در این روش نیاز به افزودن محصول به سبد خرید و تکمیل اطلاعات نیست و شما پس از وارد کردن ایمیل خود و طی کردن مراحل پرداخت لینک های دریافت محصولات را در ایمیل خود دریافت خواهید کرد.


آموزش انتقال استایل ها بوسیله PyTorch

Apache Airflow Essential Training

Building Deep Learning Models on Databricks

آموزش ساخت بلاک چین با Hyperledger

Solving Problems with Numerical Methods

Building Your First Python Analytics Solution

تجزیه و تحلیل پیش بینی شده با استفاده از Apache Spark Mllib در آژور Databricks

Foundations of PyTorch

Data Analysis Functions and Techniques in Microsoft Excel

فیلم یادگیری Employing Ensemble Methods with scikit-learn

✨ تا ۷۰% تخفیف با شارژ کیف پول 🎁
مشاهده پلن ها






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}