در حال حاضر محصولی در سبد خرید شما وجود ندارد.

این دوره به شما آموزش می دهد که چگونه داده های دسته ای را تبدیل و جمع آوری کنید با استفاده از پلت فرم Apache در پلت فرم Databricks Azure با استفاده از انتخاب، فیلتر و تجمع، توابع ساخته شده و کاربر، و انجام عملیات و پیوستن به عملیات در داده های دسته ای.
آنچه که شما یاد گرفتید
Databricks Azure اجازه می دهد تا شما را به کار با پردازش داده های بزرگ و پرس و جو با استفاده از موتور تجزیه و تحلیل Apache Spark analified. Databricks Azure اجازه می دهد تا با انواع منابع دسته ای کار کنند و اطلاعات را در پلت فرم ابر Azure تجزیه و تحلیل، تجسم، تجسم و پردازش کنند. در این دوره، داده های دسته ای را با Apache Spark در Databricks، شما یاد خواهید گرفت که چگونه به انجام تحولات و جمع آوری در داده های دسته ای با انتخاب، فیلتر کردن، گروه بندی و سفارش پرس و جو هایی که از API DataFrame استفاده می کنند. شما تفاوت بین تحولات باریک و تحولات گسترده در جرقه را درک خواهید کرد که به شما کمک می کند تا متوجه شوید که چرا تغییرات خاصی از دیگران کارآمدتر است. شما همچنین خواهید دید که چگونه می توانید این تحولات مشابه را با اجرای پرس و جو SQL بر روی داده های خود انجام دهید. بعد، شما یاد خواهید گرفت که چگونه می توانید توابع تعریف شده توسط کاربر سفارشی خود را برای پردازش داده های خود اجرا کنید. شما کد را در Notebooks Azure Databricks بنویسید تا UDF های خود را تعریف و ثبت کنید و از آنها برای انتقال اطلاعات خود استفاده کنید. شما همچنین می توانید درک کنید که چگونه تعریف و استفاده از طعم های مختلف UDFs Vectorized برای پردازش داده ها و یادگیری نحوه استفاده از UDFs های بردار اغلب کارآمدتر از UDFS معمولی است. در طول راه، شما همچنین خواهید دید که چگونه می توانید از Azure Cosmos DB به عنوان یک منبع برای اطلاعات دسته ای خود بخوانید. در نهایت، شما خواهید دید که چگونه می توانید داده های خود را در حافظه برای بهبود عملکرد پردازش بازپرداخت کنید، از توابع پنجره برای محاسبه آمار در داده های خود استفاده می کنید و فریم های داده را با استفاده از اتحادیه ها ترکیب می کنید. هنگامی که شما با این دوره به پایان رسید، مهارت ها و توانایی انجام تحولات پیشرفته و جمع آوری در داده های دسته ای، از جمله تعریف و استفاده از توابع تعریف شده توسط کاربر برای پردازش، داشته باشید.
عنوان اصلی : Handling Batch Data with Apache Spark on Databricks
سرفصل های دوره :
مرور دوره
پیش نیازها و طرح درس
Apache Spark در Databricks
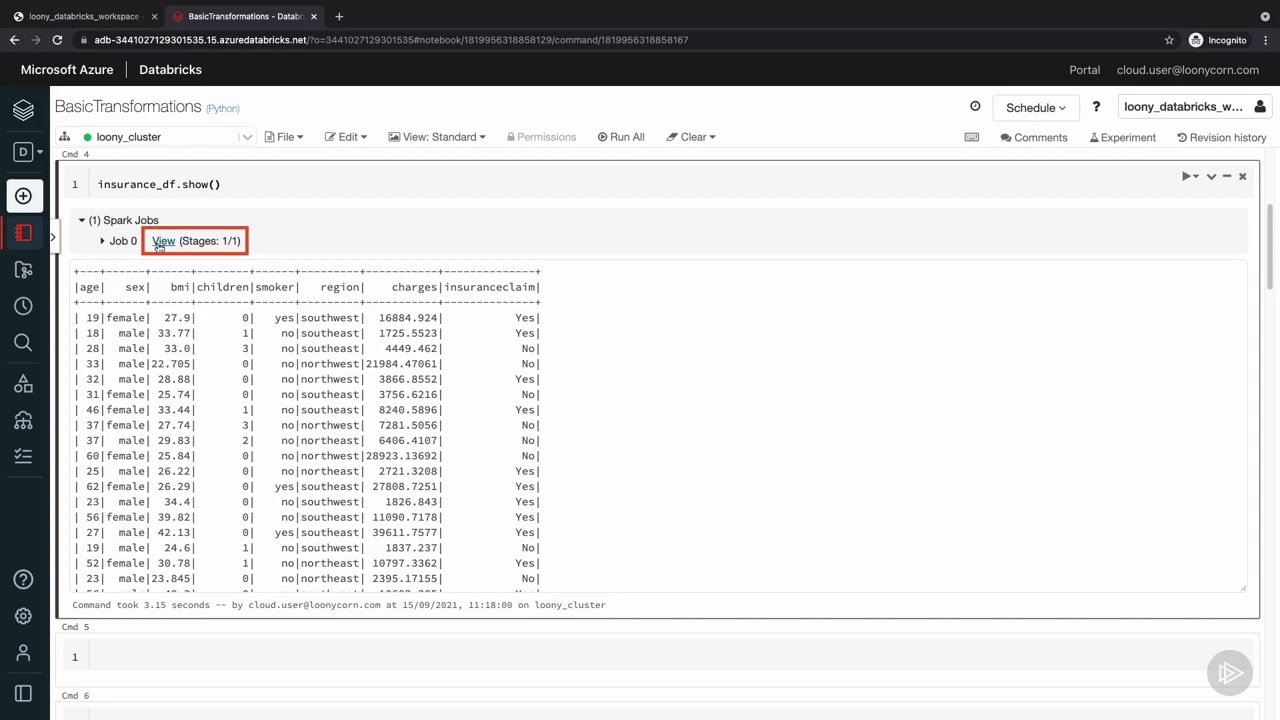
RDD ها و فریم های داده
تحولات باریک و گسترده
نسخه ی نمایشی: پیکربندی فضای کاری و خوشه
نسخه ی نمایشی: عملیات با shuffled می نویسد به دیسک
نسخه ی نمایشی: تحولات اساسی
نسخه ی نمایشی: تحولات تجمع
بهینه ساز کاتالیزور
نسخه ی نمایشی: ایجاد جدول جهانی
نسخه ی نمایشی: در حال اجرا SQL Queries در Spark
نسخه ی نمایشی: جایگزینی محتوای جدول و جداول پارتیشن بندی
نسخه ی نمایشی: در حال اجرا پرس و جوهای تعاملی در یک نوت بوک در یک خوشه همه منظوره
نسخه ی نمایشی: یک دفترچه یادداشت را به عنوان یک کار در یک خوشه شغلی اجرا کنید
توابع تعریف شده توسط کاربر (UDFS)
Vectorized UDFS
نسخه ی نمایشی: بارگیری داده ها به Cosmos DB Azure
نسخه ی نمایشی: خواندن داده ها از کیهان DB در جرقه
نسخه ی نمایشی: توابع تعریف شده توسط کاربر (UDFS)
نسخه ی نمایشی: UDFS Vectorized - سری به سری
نسخه ی نمایشی: UDFS Vectorized - enterator سری به تکرار سری
نسخه ی نمایشی: UDFS Vectorized - enterator از چندین سری به تکرار سری
نسخه ی نمایشی: UDFS Vectorized - سری به Scalar
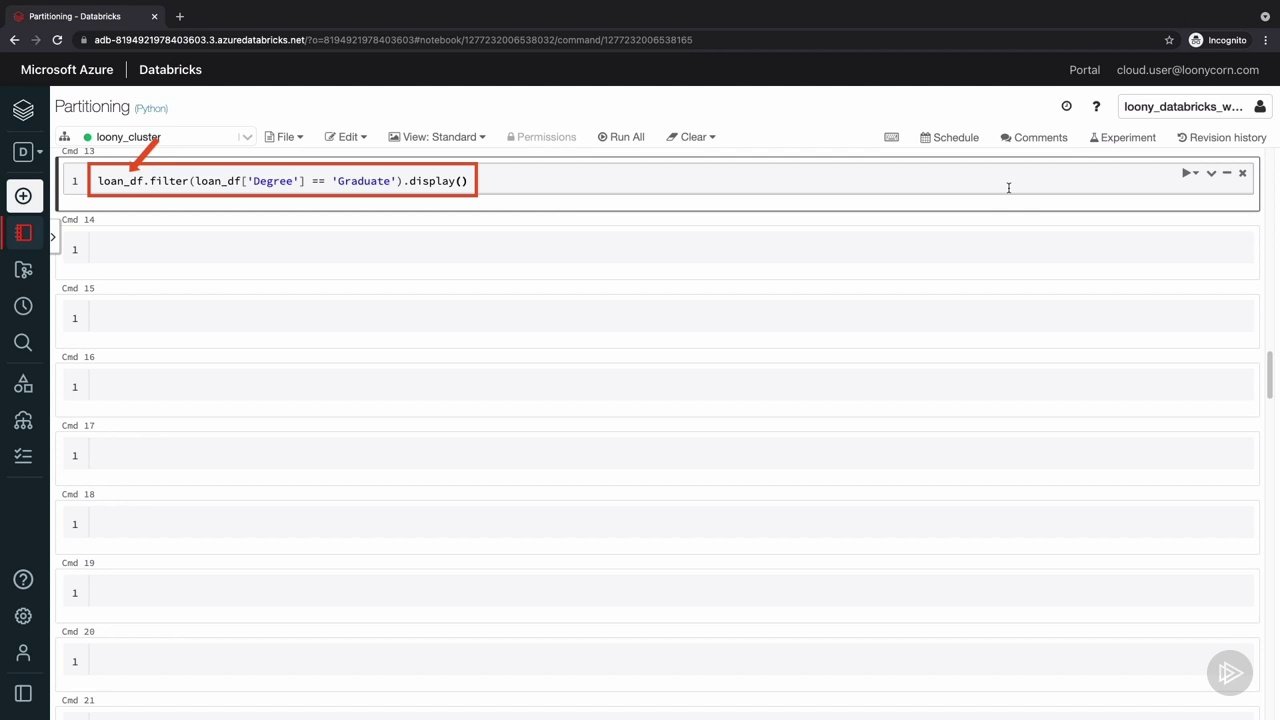
پارتیشن بندی
نسخه ی نمایشی: کار با پارتیشن های داده
نسخه ی نمایشی: داده های مجدد و جمع آوری داده ها
نسخه ی نمایشی: اجرای عملیات اتحادیه
نسخه ی نمایشی: اجرای عملیات پیوستن
توابع پنجره
فریم های ردیف و فریم های دامنه
نسخه ی نمایشی: اعمال توابع پنجره
خلاصه و مطالعه بیشتر
Handling Batch Data with Apache Spark on Databricks
در این روش نیاز به افزودن محصول به سبد خرید و تکمیل اطلاعات نیست و شما پس از وارد کردن ایمیل خود و طی کردن مراحل پرداخت لینک های دریافت محصولات را در ایمیل خود دریافت خواهید کرد.


Learning Apache Airflow

آموزش مبانی TensorFlow

آموزش مدل سازی داده های استریمینگ بوسیله Apache Beam SDK

یادگیری ماشینی برای خدمات مالی

آموزش داده یابی یا همان Data Mining از متون

آموزش ساخت مدل های Machine Learning

Data Labeling for Machine Learning

Understanding Statistical Models and Mathematical Models

فیلم یادگیری کامل Evaluating a Data Mining Model

Troubleshooting and Debugging Kafka

✨ تا ۷۰% تخفیف با شارژ کیف پول 🎁
مشاهده پلن ها






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}