در حال حاضر محصولی در سبد خرید شما وجود ندارد.

به عنوان یک توسعه دهنده، شما مطمئنا درباره ساختارهای مختلف داده ها و الگوریتم ها شنیده اید. با این حال، آیا تا به حال عمیقا در مورد آنها و تاثیر آنها بر عملکرد برنامه های خود فکر کرده اید؟ اگر نه، وقت آن است که به این موضوع نگاه کنید، و این دوره یک راهنمای یکپارچه برای استاد آن است!
این دوره به شما تئوری و برنامه های لازم را به شما آموزش می دهد تا به درستی درک الگوریتم های پیشرفته و ساختارهای داده را به شما آموزش دهد که برای مشکلات مختلف و نحوه اجرای آنها حیاتی هستند. ما همچنین دست ها و نکات و ترفندهای بهینه سازی ها را نشان خواهیم داد، شناسایی رویکردهای مناسب و ارائه توضیحات قانع کننده. و شما آن را در یک زبان مدرن، محبوب و به خوبی مستند دریافت خواهید کرد: پایتون. در نهایت، شما خواهید آموخت که چگونه الگوریتم های پیچیده ای را که آسان برای درک، اشکال زدایی و قابل استفاده مجدد در برنامه های مختلف وجود دارد، یاد بگیرند.
در پایان دوره، شما می دانید که چگونه برای توسعه الگوریتم های پیچیده ای که آسان برای درک است ، اشکال زدایی، و قابل استفاده مجدد در برنامه های مختلف.
عنوان اصلی : Advanced Algorithms Data
سرفصل های دوره :
01 - فصل 1 معرفی ساختارهای داده
02 - بخش 1. بهبود ساختارهای داده پایه
03 - فصل 1 توصیف ساختار داده
04 - فصل 1 بسته بندی کوله پشتی - ساختارهای داده با دنیای واقعی مطابقت دارند
05 - فصل 1 الگوریتم هایی برای نجات
06 - فصل 2 بهبود صفهای اولویت - انبوههای d-way
07 - فصل 2 راه حل های موجود - نگه داشتن یک لیست مرتب شده
08 - فصل 2 ساختارهای داده بتن
09 - فصل 2 اولویت، حداقل هیپ، و حداکثر هیپ
10 - فصل 2 نحوه پیاده سازی پشته
11 - فصل 2 PushDown
12 - فصل 2 بالا
13 - فصل 2 Heapify
14 - فصل 2 مورد استفاده - k بزرگترین عنصر را پیدا کنید
15 - فصل 2 موارد استفاده بیشتر
16 - فصل 2 تجزیه و تحلیل عامل انشعاب
17 - فصل 2 تجزیه و تحلیل عملکرد - یافتن بهترین عامل انشعاب
18 - فصل 2 تفسیر نتایج
19 - فصل 2 رمز و راز با heapify
20 - فصل 3 Treaps - استفاده از تصادفی سازی برای تعادل درختان جستجوی دودویی
21 - فصل 3 تراپ
22 - فصل 3 چند سوال طراحی
23 - فصل 3 حذف
24 - فصل 3 کاربردها - تپه های تصادفی
25 - فصل 3 تجزیه و تحلیل عملکرد و پروفایل
26 - فصل 3 پروفایل ارتفاع
27 - فصل 3 پروفایل استفاده از حافظه
28 - فصل 4 فیلترهای بلوم - کاهش حافظه برای ردیابی محتوا
29 - فصل 4 گزینه های جایگزین برای پیاده سازی فرهنگ لغت
30 - فصل 4 ساختارهای داده بتن
31 - فصل 4 درخت جستجوی دودویی - هر عملیات لگاریتمی است
32 - فصل 4 اجرا
33 - فصل 4 سازنده
34 - فصل 4 کاربردها
35 - فصل 4 چرا فیلترهای بلوم کار می کنند
36 - فصل 4 تجزیه و تحلیل عملکرد
37 - فصل 4 توضیح فرمول نسبت مثبت کاذب
38 - فصل 4 انواع بهبود یافته
39 - فصل 5 مجموعه های ناهمگون - پردازش زمان فرعی
40 - فصل 5 استدلال در مورد راه حل ها
41 - فصل 5 راه حل ساده
42 - فصل 5 استفاده از ساختار درخت مانند
43 - فصل 5 اکتشافی برای بهبود زمان اجرا
44 - فصل 5 کاربردها
45 - Chapter 6 Trie، radix trie - جستجوی رشته کارآمد
46 - فصل 6 امتحان کنید
47 - فصل 6 جستجو
48 - فصل 6 درج
49 - فصل 6 کلیدهای مطابق با پیشوند
50 - فصل 6 رادیکس تلاش می کند
51 - فصل 6 جستجو
52 - فصل 6 کاربردها
53 - فصل 6 مرتب سازی رشته ها
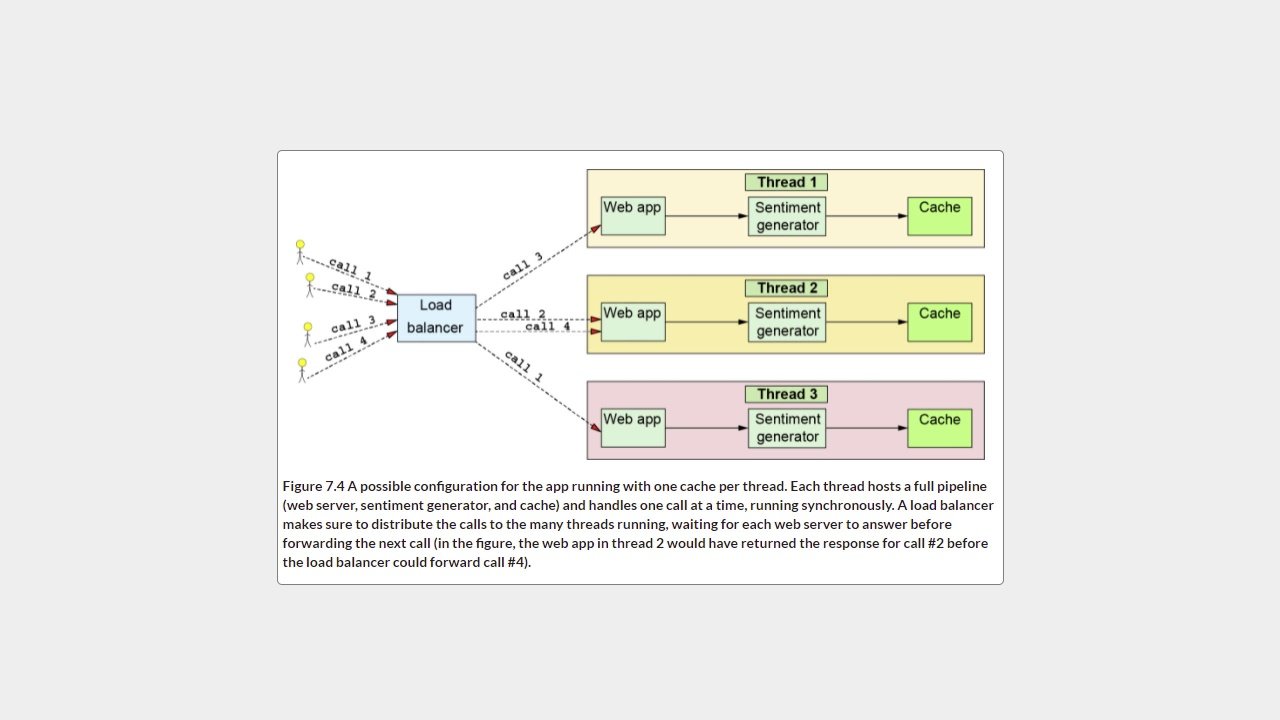
54 - فصل 7 مورد استفاده - حافظه پنهان LRU
55 - فصل 7 اولین تلاش - به خاطر سپردن مقادیر
56 - فصل 7 رسیدگی به تماسهای ناهمزمان
57 - فصل 7 حافظه کافی نیست (به معنای واقعی کلمه)
58 - فصل 7 خلاص شدن از دست داده های قدیمی - حافظه پنهان LRU
59 - فصل 7 ترتیب زمانی
60 - فصل 7 وقتی دادههای تازهتر ارزش بیشتری دارند - LFU
61 - فصل 7 نحوه استفاده از حافظه پنهان به همان اندازه مهم است
62 - فصل 7 حل همزمانی (در جاوا)
63 - فصل 7 قفل ها را بخوانید
64 - قسمت 2. پرس و جوهای چند بعدی
65 - فصل 8 جستجوی نزدیکترین همسایگان
66 - فصل 8 ساده کردن چیزها برای دریافت راهنمایی
67 - فصل 8 حرکت به فضاهای k بعدی
68 - فصل 9 درختان K-d - نمایه سازی داده های چند بعدی
69 - فصل 9 ساخت BST
70 - فصل 9 روشها
71 - فصل 9 درخت متعادل
72 - فصل 9 حذف
73 - فصل 9 نزدیکترین همسایه
74 - فصل 9 جستجوی منطقه
75 - فصل 10 درختان جستجوی تشابه - جستجوی تقریبی نزدیکترین همسایگان برای بازیابی تصویر
76 - فصل 10 R-tree
77 - فصل 10 درج نقاط در درخت R
78 - فصل 10 درخت جستجوی تشابه
79 - فصل 10 جستجوی SS-tree
80 - درج فصل 10
81 - فصل 10 درج - تقسیم گره ها
82 - فصل 10 حذف
83 - فصل 10 جستجوی تشابه
84 - فصل 10 جستجوی شباهت تقریبی
85 - فصل 10 SS+-tree
86 - فصل 10 کاهش همپوشانی
87 - فصل 11 کاربردهای جستجوی نزدیکترین همسایه
88 - فصل 11. کاربرد متمرکز
89 - فصل 11 انتقال به یک برنامه کاربردی توزیع شده
90 - فصل 11 سایر برنامه ها
91 - فصل 11 بهینه سازی پرس و جوهای DB چند بعدی
92 - فصل 12 خوشه بندی
93 - فصل 12 انواع یادگیری
94 - فصل 12 ک - معنی
95 - فصل 12 نفرین ابعاد دوباره می آید
96 - فصل 12 تقویت k-means با درختان k-d
97 - فصل 12 DBSCAN
98 - فصل 12 از تعاریف تا یک الگوریتم
99 - فصل 12 و در نهایت، یک پیاده سازی
100 - فصل 12 اپتیک
101 - فصل 12 از فاصله دسترسی تا خوشه بندی
102 - فصل 12 خوشه بندی سلسله مراتبی
103 - فصل 12. ارزیابی نتایج خوشه بندی - معیارهای ارزیابی
104 - فصل 13 خوشه بندی موازی - MapReduce و خوشه بندی تاج
105 - فصل 13 خوشه بندی سایبان
106 - فصل 13 MapReduce
107 - فصل 13 ابتدا نقشه، سپس کاهش دهید
108 - فصل 13 MapReduce k-means
109 - فصل 13 موازی کردن سایبانy خوشه بندی
110 - فصل 13 نقشه کاهش خوشه بندی سایه بان
111 - فصل 13 MapReduce DBSCAN - قسمت 1
112 - فصل 13 MapReduce DBSCAN - قسمت 2
113 - قسمت 3. نمودارهای مسطح و حداقل تعداد تقاطع
114 - فصل 14 مقدمه ای بر نمودارها - یافتن مسیرهایی با حداقل فاصله
115 - فصل 14 پیاده سازی نمودارها
116 - فصل 14 ویژگی های نمودار
117 - فصل 14 پیمایش نمودار - BFS و DFS
118 - فصل 14 بازسازی مسیر به هدف
119 - فصل 14 کوتاهترین مسیر در نمودارهای وزنی - Dijkstra
120 - فصل 14 فراتر از الگوریتم دایکسترا - A
121 - فصل 14 جستجوی A_ چقدر خوب است
122 - فصل 14 اکتشافی به عنوان راهی برای تعادل داده های زمان واقعی
123 - فصل 15 تعبیه نمودارها و مسطح بودن - رسم نمودارها با حداقل تقاطع لبه ها
124 - فصل 15 برخی از تعاریف اساسی
125 - فصل 15 نمودارهای مسطح
126 - فصل 15 تست مسطح
127 - فصل 15 بهبود عملکرد
128 - فصل 15 نمودارهای غیر مسطح
129 - فصل 15 شماره تقاطع مستطیل
130 - فصل 15 تقاطع لبه ها
131 - فصل 15 چند خطوط
132 - فصل 15 تقاطع بین منحنی های درجه دوم بزیه
133 - فصل 16 نزول گرادیان - مشکلات بهینه سازی (نه فقط) در نمودارها
134 - فصل 16 آیا شما فقط اکتشافی را گفتید؟
135 - فصل 16 چگونه بهینه سازی کار می کند
136 - فصل 16 نزول گرادیان
137 - فصل 16 چه زمانی نزول گرادیان قابل اعمال است
138 - فصل 16 کاربردهای شیب نزول
139 - فصل 16 نزول گرادیان برای جاسازی نمودار
140 - فصل 17 بازپخت شبیه سازی شده - بهینه سازی فراتر از حداقل های محلی
141 - فصل 17 گاهی اوقات برای رسیدن به پایین باید از بالا بالا بروید
142 - فصل 17 چرا بازپخت شبیه سازی شده کار می کند؟
143 - فصل 17 انتقال کوتاه برد در مقابل دوربرد
144 - فصل 17 بازپخت شبیه سازی شده + فروشنده دوره گرد
145 - فصل 17 راه حل های دقیق در مقابل تقریبی
146 - فصل 17 انتقال حالت
147 - فصل 17 بازپخت شبیه سازی شده و تعبیه گراف
148 - فصل 17 ترسیم با هدایت نیرو
149 - فصل 18 الگوریتم های ژنتیک - بهینه سازی سریع با الهام از بیولوژیک
150 - فصل 18 با الهام از طبیعت
151 - فصل 18 کروموزوم ها
152 - فصل 18 انتخاب طبیعی
153 - فصل 18 انتخاب افراد برای جفت گیری
154 - فصل 18 متقاطع
155 - فصل 18 الگوریتم ژنتیک
156 - فصل 18 TSP
157 - فصل 18 تنظیم نتایج و پارامترها
158 - فصل 18 حداقل پوشش راس
159 - فصل 18 سایر کاربردهای الگوریتم ژنتیک
160 - فصل 18 فراتر از الگوریتم های ژنتیک
161 - ضمیمه الف. راهنمای سریع شبه کد
162 - ضمیمه A دستورالعمل های مشروط
163 - ضمیمه A بلوک ها و تورفتگی ها
164 - ضمیمه B. نماد Big-O
165 - ضمیمه B نماد
166 - پیوست ج. ساختارهای داده اصلی
167 - درخت ضمیمه C
168 - جدول هش پیوست C
169 - ضمیمه د. کانتینرها به عنوان صف اولویت
170 - ضمیمه E. بازگشت
171 - پیوست E بازگشت دم
172 - ضمیمه F. مشکلات طبقه بندی و معیارهای الگوریتم تصادفی
173 - ضمیمه F معیارهای طبقه بندی
Advanced Algorithms Data
در این روش نیاز به افزودن محصول به سبد خرید و تکمیل اطلاعات نیست و شما پس از وارد کردن ایمیل خود و طی کردن مراحل پرداخت لینک های دریافت محصولات را در ایمیل خود دریافت خواهید کرد.


✨ تا ۷۰% تخفیف با شارژ کیف پول 🎁
مشاهده پلن ها






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}