جمع جزء: 189,000 تومان
- × 1 عدد: آموزش رخدادها و Listener ها در Slim 4 - 189,000 تومان
خوشه بندی - یک رویکرد یادگیری ماشین بدون نظارت که برای گروه بندی داده ها بر اساس شباهت استفاده می شود - برای کار در تجزیه و تحلیل شبکه ، تقسیم بازار ، گروه بندی نتایج جستجو ، تصویربرداری پزشکی و تشخیص ناهنجاری استفاده می شود. خوشه بندی k-mean یکی از محبوب ترین و آسان ترین الگوریتم های خوشه بندی است. در این دوره ، فرد Nwanganga نگاهی مقدماتی به خوشه بندی K به شما می دهد-نحوه عملکرد آن ، چه چیزی برای آن خوب است ، وقتی باید از آن استفاده کنید ، چگونه می توانید تعداد مناسب خوشه ها ، نقاط قوت و ضعف آن و موارد دیگر را انتخاب کنید. فرد راهنمایی های مفیدی در مورد چگونگی جمع آوری ، کاوش و تبدیل داده ها در آماده سازی داده های تقسیم بندی با استفاده از خوشه بندی K ارائه می دهد ، و یک راهنمای گام به گام در مورد چگونگی ساخت چنین مدلی در پایتون ارائه می دهد.
عنوان اصلی : Machine Learning with Python: k-Means Clustering
سرفصل های دوره :
مقدمه:
شروع با خوشه بندی پایتون و k-means
آنچه باید بدانید
ابزارهای مورد نیاز شما
با استفاده از پرونده های ورزش
1. درک خوشه بندی k-mean:
خوشه بندی چیست؟
K-Means خوشه بندی چیست؟
انتخاب تعداد مناسب خوشه ها
چرا و چه موقع از خوشه بندی k-mean استفاده می کنیم
2. تقسیم داده ها با خوشه بندی k-mean:
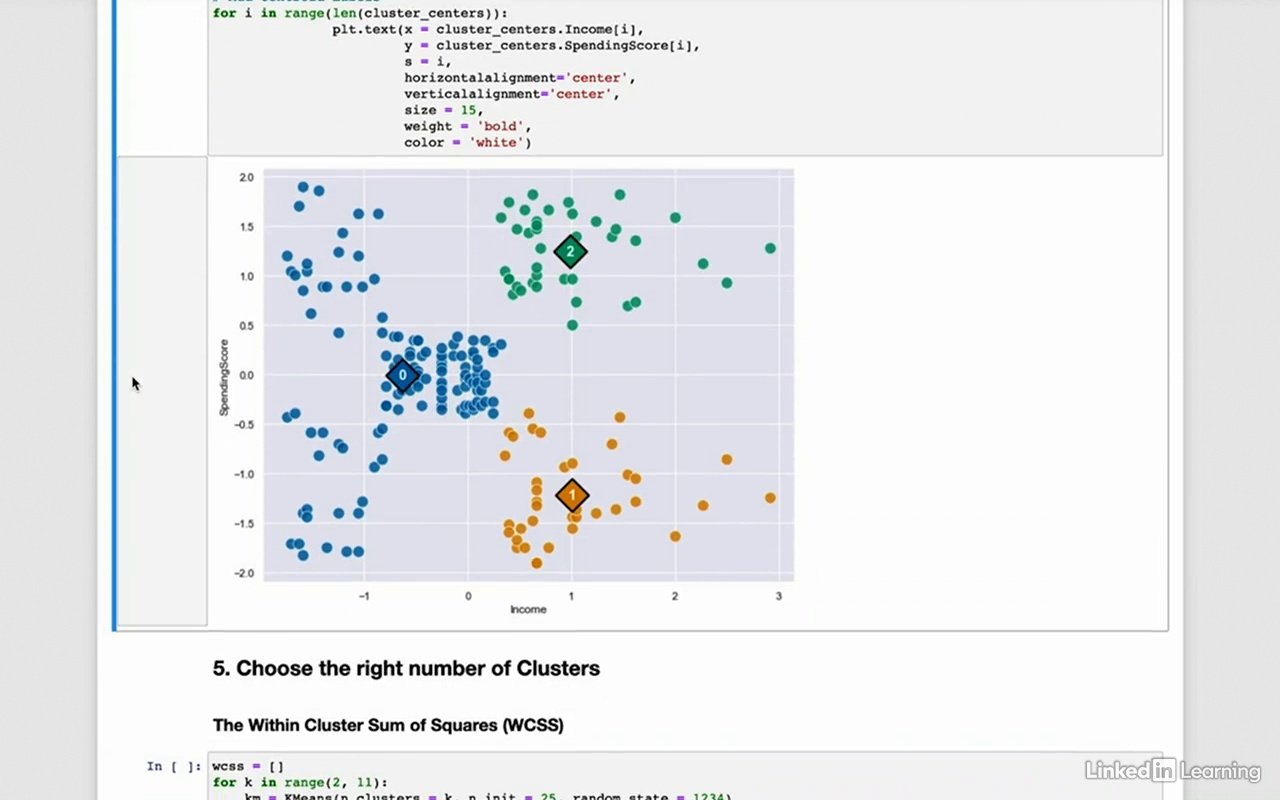
نحوه تقسیم داده ها با خوشه بندی k-mean در پایتون
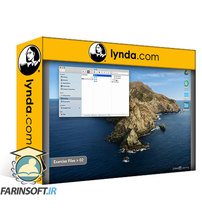
نحوه ارزیابی و تجسم خوشه ها در پایتون
نحوه یافتن تعداد مناسب خوشه ها در پایتون
نحوه تفسیر نتایج خوشه بندی k-mean در پایتون
نتیجه گیری:
مراحل بعدی
Machine Learning with Python: k-Means Clustering
در این روش نیاز به افزودن محصول به سبد خرید و تکمیل اطلاعات نیست و شما پس از وارد کردن ایمیل خود و طی کردن مراحل پرداخت لینک های دریافت محصولات را در ایمیل خود دریافت خواهید کرد.


✨ تا ۷۰% تخفیف با شارژ کیف پول 🎁
مشاهده پلن ها








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}