در حال حاضر محصولی در سبد خرید شما وجود ندارد.

آماده سازی داده ها ممکن است مهمترین بخش پروژه یادگیری ماشین باشد. این بخش زمان مصرف کننده است، اگر چه این موضوع مورد بحث است. آماده سازی داده ها، گاهی اوقات به عنوان پیش پردازش داده ها اشاره می شود، عمل تبدیل داده های خام به شکل مناسب برای مدل سازی است.
الگوریتم های یادگیری ماشین نیاز به داده های ورودی را به شماره گذاری می کنند و اکثر پیاده سازی الگوریتم این انتظارات را حفظ می کند. بنابراین، اگر اطلاعات شما شامل انواع داده ها و مقادیر که اعداد نیست، مانند برچسب ها، شما باید داده ها را به اعداد تغییر دهید. علاوه بر این، الگوریتم های یادگیری ماشین خاص، انتظارات مربوط به انواع داده ها، مقیاس، توزیع احتمالی و روابط بین متغیرهای ورودی را دارند و ممکن است نیاز به تغییر داده ها برای پاسخگویی به این انتظارات داشته باشید.
در این دوره، شما اطلاعات را یاد خواهید گرفت و تکنیک های پاکسازی داده های پیشرفته، نحوه استفاده از تکنیک های پاکسازی اطلاعات دنیای واقعی به داده های شما، تکنیک های پاکسازی داده های پیشرفته. همچنین، نحوه آماده سازی داده ها را به نحوی که از نشت داده ها اجتناب می کند و به نوبه خود ارزیابی مدل نادرست را انجام دهید.
در پایان این دوره، شما پیش پردازش داده ها و مهارت های تمیز کردن داده ها را انجام می دهید.
بسته نرم افزاری کامل برای این دوره در https://github.com/packtpublishing/data-cleansing-master-class-in-python در دسترس است
عنوان اصلی : Data Cleansing Master Class in Python
سرفصل های دوره :
مقدمه:
معرفی دوره
ساختار دوره
آیا این دوره برای شما مناسب است؟
مبانی:
معرفی آماده سازی داده ها
فرایند یادگیری ماشین
آماده سازی داده ها تعریف شده است
انتخاب تکنیک آماده سازی داده
داده در یادگیری ماشینی چیست؟
داده های خام
یادگیری ماشینی عمدتاً آماده سازی داده است
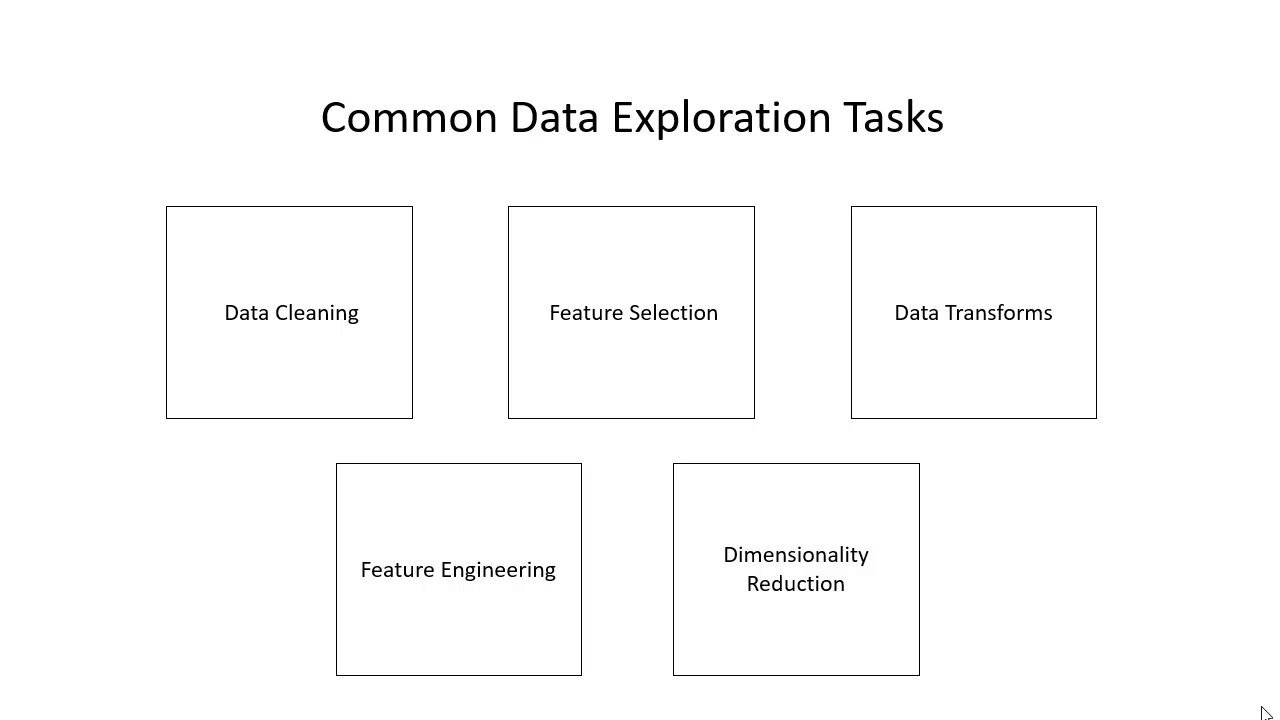
وظایف متداول آماده سازی داده - پاکسازی داده ها
وظایف متداول آماده سازی داده - انتخاب ویژگی
وظایف متداول آماده سازی داده - تبدیل داده ها
وظایف متداول آماده سازی داده - مهندسی ویژگی
وظایف متداول آماده سازی داده - کاهش ابعاد
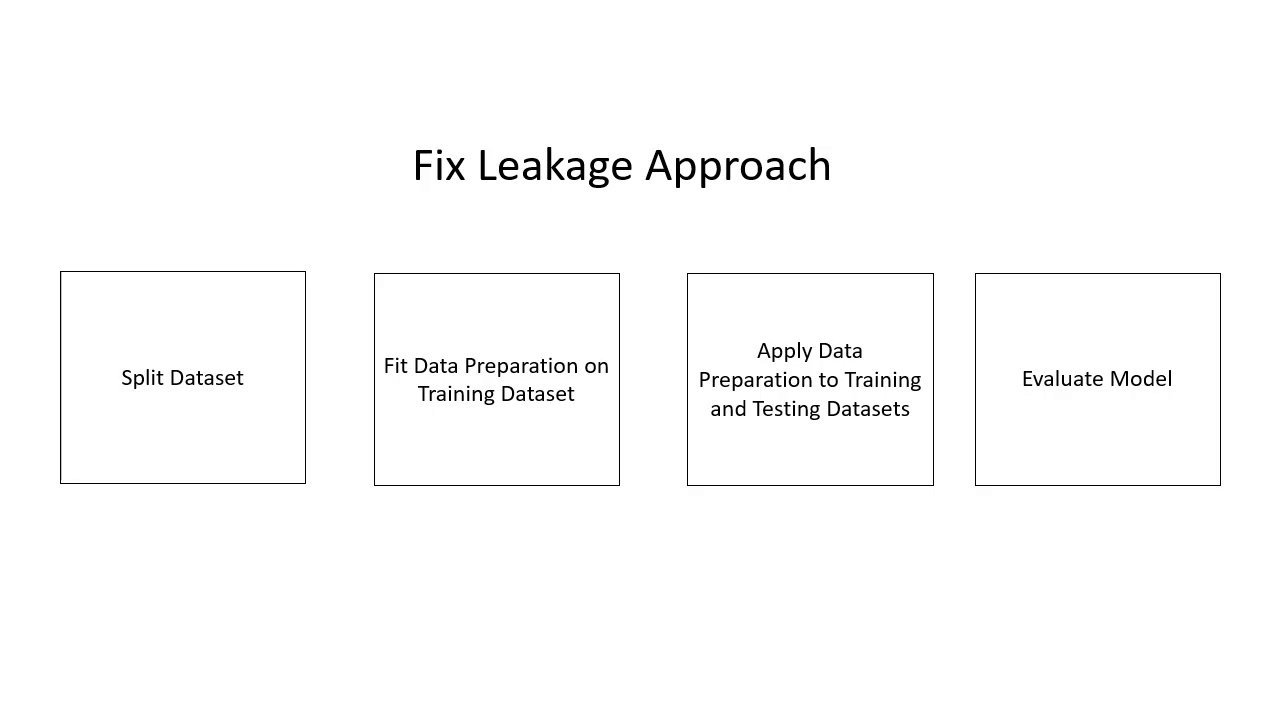
نشت داده ها
مشکل با آمادهسازی دادههای ساده
مطالعه موردی: نشت داده: قطار / آزمایش / رویکرد ساده لوح تقسیم
مطالعه موردی: نشت داده ها: قطار / آزمایش / تقسیم رویکرد صحیح
مطالعه موردی: نشت داده: رویکرد ساده لوح K-Fold
مطالعه موردی: نشت داده: رویکرد صحیح K-Fold
پاکسازی داده ها:
نمای کلی پاکسازی داده ها
ستون هایی را که دارای یک مقدار واحد هستند شناسایی کنید
ستون هایی با مقادیر کم را شناسایی کنید
حذف ستون های با واریانس کم
ردیف هایی که حاوی داده های تکراری هستند را شناسایی و حذف کنید
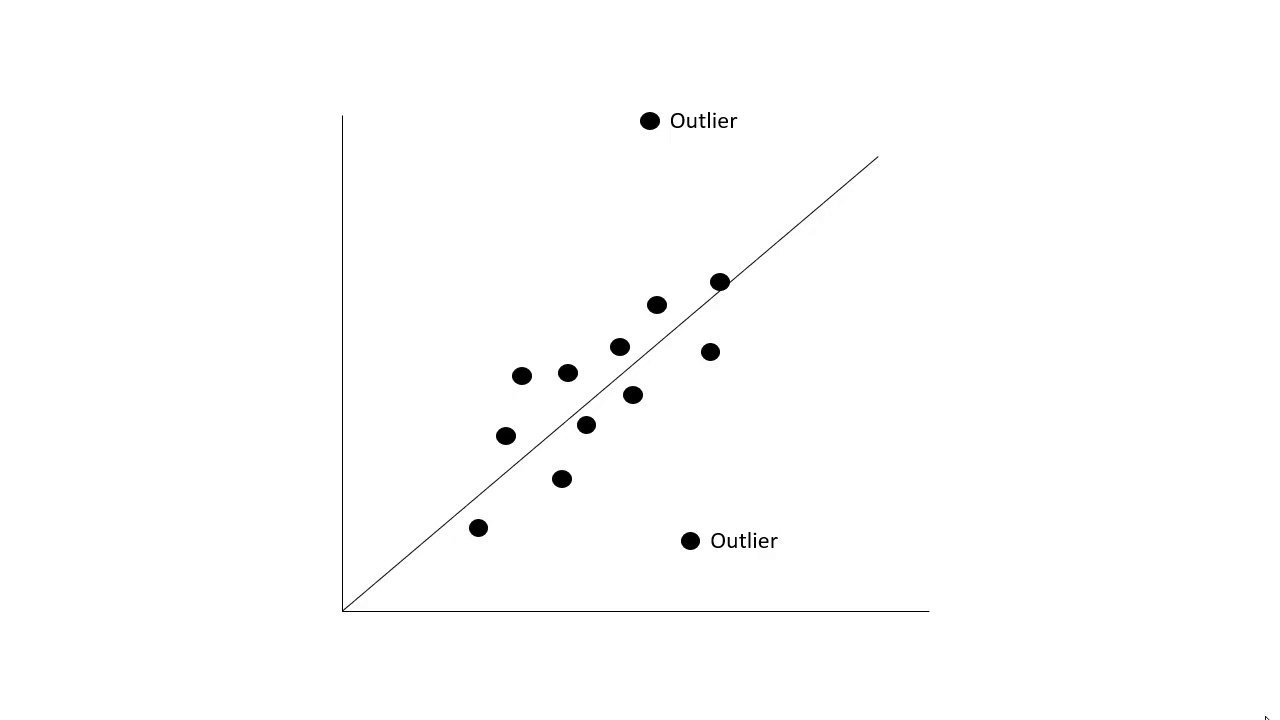
تعریف نقاط پرت
حذف Outliers - رویکرد انحراف استاندارد
حذف Outliers - رویکرد IQR
تشخیص خودکار نقاط بیرونی
مقادیر گمشده را علامت گذاری کنید
ردیف های دارای مقادیر از دست رفته را حذف کنید
تحریر آماری
انتصاب مقدار میانگین
Imputer ساده با ارزیابی مدل
مقایسه راهبردهای انتساب آماری مختلف
K-نزدیکترین همسایهها
KNNI کامپیوتر و ارزیابی مدل
Iterative Imputation
IterativeImputer و ارزیابی مدل
IterativeImputer و Different Imputation Order
انتخاب ویژگی:
معرفی انتخاب ویژگی
انتخاب ویژگی تعریف شده است
آمار برای انتخاب ویژگی
بارگیری یک مجموعه داده دسته بندی شده
مجموعه داده را برای مدلسازی رمزگذاری کنید
Chi-Squared
اطلاعات متقابل
مدل سازی با ویژگی های دسته بندی انتخاب شده
انتخاب ویژگی با ANOVA در ورودی عددی
انتخاب ویژگی با اطلاعات متقابل
مدل سازی با ویژگی های عددی منتخب
تنظیم تعدادی از ویژگی های انتخاب شده
ویژگی ها را برای خروجی عددی انتخاب کنید
همبستگی خطی با آمار همبستگی
همبستگی خطی با اطلاعات متقابل
خط مبنا و مدل با استفاده از همبستگی ساخته شده است
مدل ساخته شده با استفاده از ویژگی های اطلاعات متقابل
تنظیم تعداد ویژگیهای انتخابی
حذف ویژگی بازگشتی
RFE برای طبقه بندی
RFE برای رگرسیون
هایپرپارامترهای RFE
رتبه بندی ویژگی برای RFE
نمرات اهمیت ویژگی تعریف شده است
امتیازهای اهمیت ویژگی: رگرسیون خطی
امتیازات اهمیت ویژگی: رگرسیون لجستیک و سبد خرید
امتیازات اهمیت ویژگی: جنگل های تصادفی
اهمیت ویژگی جایگشت
انتخاب ویژگی با اهمیت
تبدیل داده ها:
مقیاس داده های عددی
مجموعه داده های دیابت برای مقیاس بندی
تبدیل MinMaxScaler
StandardScaler Transform
داده های مقیاس پذیری قوی
مقیاسکننده قوی برای مجموعه داده اعمال شد
محدوده مقیاسکننده قوی را کاوش کنید
متغیرهای اسمی و ترتیبی
رمزگذاری ترتیبی
کدگذاری یک داغ تعریف شده است
کدگذاری تک داغ
رمزگذاری متغیر ساختگی
تبدیل رمزگذار ترتیبی در مجموعه داده سرطان پستان
توزیعات را گاوسی تر کنید
تبدیل نیرو در مجموعه داده های ساختگی
تبدیل نیرو در مجموعه داده سونار
Box-Cox در مجموعه داده سونار
Yeo-Johnson در مجموعه داده سونار
ویژگی های چند جمله ای
اثر درجات چند جمله ای
تبدیلهای پیشرفته:
تغییر انواع داده های مختلف
ClumnTransformer
ClumnTransformer در مجموعه داده Abalone
تغییر تغییر هدف دستی
تغییر خودکار متغیر هدف
چالش آماده سازی داده های جدید برای یک مدل
Save Model and Data Scaler
مقیاسکنندههای ذخیرهشده را بارگیری و اعمال کنید
کاهش ابعاد:
نفرین ابعاد
تکنیک هایی برای کاهش ابعاد
تحلیل تشخیصی خطی
تحلیل تشخیصی خطی نشان داده شد
تحلیل مولفه اصلی
Data Cleansing Master Class in Python
در این روش نیاز به افزودن محصول به سبد خرید و تکمیل اطلاعات نیست و شما پس از وارد کردن ایمیل خود و طی کردن مراحل پرداخت لینک های دریافت محصولات را در ایمیل خود دریافت خواهید کرد.


How You Can Master the Fundamentals of Transact-SQL

آموزش انجام پروژه های یادگیری ماشینی در کلود گوگل با BigQuery

Data Visualization in Python for Machine Learning Engineers

یادگیری ماشینی کاربردی با Bigquery در Google Cloud
آموزش مهاجرت دیتابیس های SQL Server به درون Amazon RDS

آموزش کار با داده های عددی در آژور

مهندسی یادگیری ماشینی بوسیله Python Keras

بهبود کارایی یادگیری عمیق ( دیپ لرنینگ ) در زبان Python

نوشتن مدل های یادگیری ماشینی از ابتدا

Building Features from Nominal and Numeric Data in Microsoft Azure

✨ تا ۷۰% تخفیف با شارژ کیف پول 🎁
مشاهده پلن ها






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}