در حال حاضر محصولی در سبد خرید شما وجود ندارد.

در این دوره آموزشی قدم به قدم یاد می گیرید که چطور تحلیل بیگ دیتا را بوسیله Hadoop and Apache Spark انجام دهید.
عنوان اصلی : Big Data Analytics with Hadoop and Apache Spark
معرفی
قدرت ترکیبی Spark و Hadoop Distributed File System (HDFS)
1. معرفی و راه اندازی
نمای کلی آپاچی هادوپ
نمای کلی آپاچی اسپارک
ادغام Hadoop و Spark
راه اندازی محیط
استفاده از فایل های تمرینی
2. مدل سازی داده HDFS برای تجزیه و تحلیل
فرمت های ذخیره سازی
فشرده سازی
پارتیشن بندی
سطل سازی
بهترین روش ها برای ذخیره سازی داده ها
3. بلع داده ها با Spark
خواندن فایل های خارجی در Spark
نوشتن به HDFS
موازی می نویسد با پارتیشن بندی
موازی با سطل می نویسد
بهترین روش ها برای بلعیدن
4. استخراج داده ها با اسپارک
اسپارک چگونه کار می کند
خواندن فایل های HDFS با طرحواره
خواندن داده های پارتیشن بندی شده
خواندن داده های سطلی
بهترین روش ها برای استخراج داده ها
5. بهینه سازی پردازش جرقه
پایین آوردن پیش بینی ها
فشار دادن فیلترها
مدیریت پارتیشن ها
مدیریت زدن
بهبود اتصالات
ذخیره سازی نتایج متوسط
بهترین روش ها برای پردازش داده ها
6. از پروژه Case استفاده کنید
تعریف مشکل
بارگذاری داده ها
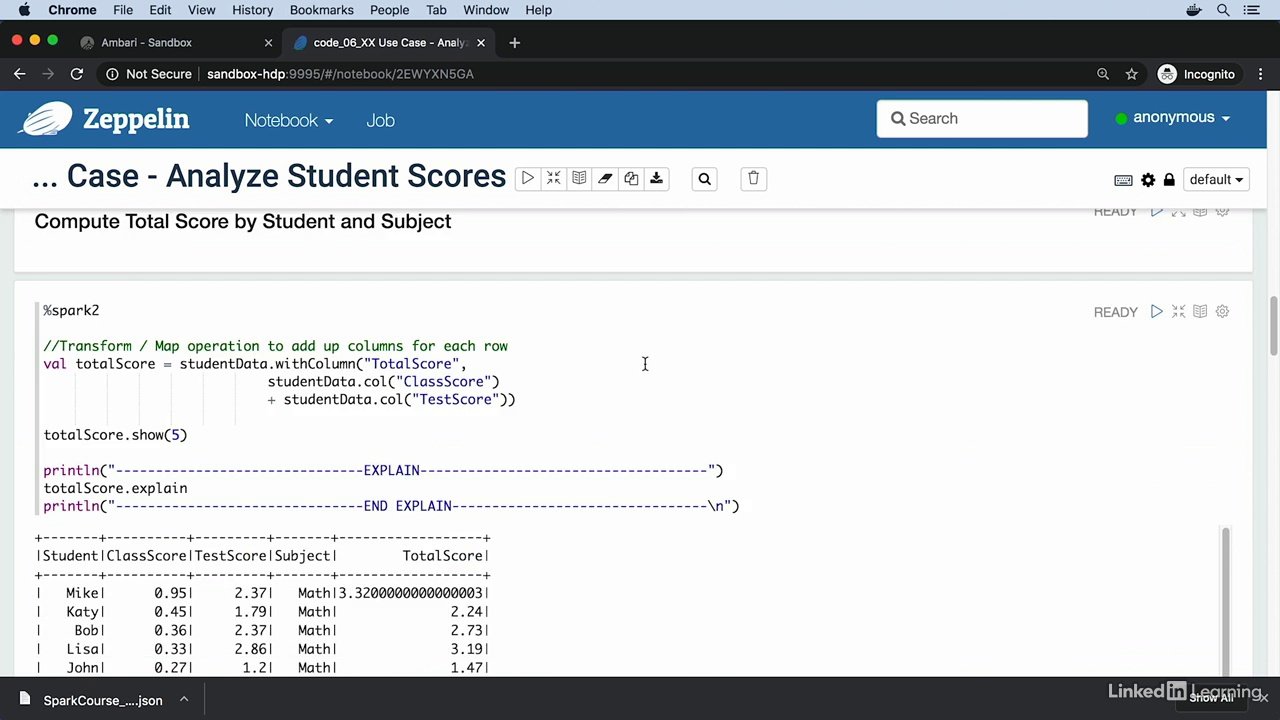
تجزیه و تحلیل نمره کل
تجزیه و تحلیل میانگین امتیاز
تجزیه و تحلیل برتر دانش آموزان
نتیجه
مراحل بعدی
Big Data Analytics with Hadoop and Apache Spark
در این روش نیاز به افزودن محصول به سبد خرید و تکمیل اطلاعات نیست و شما پس از وارد کردن ایمیل خود و طی کردن مراحل پرداخت لینک های دریافت محصولات را در ایمیل خود دریافت خواهید کرد.


آموزش آنالیز متون بوسیله زبان R
-main-resized.jpg)
کورس شبکه های عصبی مکرر

تجزیه و تحلیل متن و پیش بینی بوسیله کدنویسی در زبان Python

شبکه های عصبی مکرر

آموزش اعمال و استفاده از هوش مصنوعی در IT

Applied AI: Building NLP Apps with Hugging Face Transformers

MLOps Essentials: Monitoring Model Drift and Bias

Data Science on Google Cloud Platform: Designing Data Warehouses

معماری برنامه های کاربردی داده های بزرگ

LLM Foundations: Vector Databases for Caching and Retrieval Augmented Generation (RAG)

✨ تا ۷۰% تخفیف با شارژ کیف پول 🎁
مشاهده پلن ها






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}