در حال حاضر محصولی در سبد خرید شما وجود ندارد.

پروژه برنامه اسکنر سند را توسعه دهید که استخراج موجودیت از اسکن اسکن با OpenCV، Pytesseract، Spacy
عنوان اصلی : Intelligently Extract Text & Data from Document with OCR NER
سرفصل های دوره :
مقدمه:
منابع را دانلود کنید
با مشکلی در دوره مواجه هستید؟ راه حل اینجاست
تنظیم پروژه:
پایتون را نصب کنید
محیط مجازی را نصب کنید
بسته ها را در محیط مجازی نصب کنید
Tesseract OCR و Pytesseract را نصب کنید
SpaCy را نصب کنید
تست کنید، بسته ها نصب شده اند
آماده سازی داده ها:
کارت ویزیت را با استفاده از OpenCV & PIL بارگیری کنید
Pytesseract: خطای Tesseract
Pytesseract: تصویر به متن به دیتافریم
Pytesseract: متن پاک در Dataframe
متن و داده ها را از تمام کارت ویزیت استخراج کنید
ذخیره داده ها در csv
برچسب گذاری
پیش پردازش و پاکسازی داده ها:
فرمت داده های آموزش فضایی
داده ها را بارگیری کنید و به Pandas DataFrame تبدیل کنید
پاک کردن متن
تبدیل داده ها به فرمت فضایی
نهادهای آزمایشی
تبدیل داده ها به فرمت فضایی برای تمام متن های کارت ویزیت
تقسیم داده ها به مجموعه آموزشی و آزمایشی
مدل شناسایی نهاد با نام قطار (NER):
Spacy: پیکربندی را پر کنید
Spacy: داده ها را آماده کنید
فضا: مدل خط لوله قطار NER
Spacy: Save Model NER
پیشبینیها:
وارد کردن کتابخانه های مورد نیاز
عملکرد متن پاک
مدل NER فضای بارگذاری
متن را از تصویر استخراج کرده و به قاب داده تبدیل کنید
فریم داده را به محتوا تبدیل کنید
نهادهای نامگذاری شده را از مدل دریافت کنید
رندر دیسپلی
برچسب کردن هر کلمه
به Label به قالب داده توکن بپیوندید
به dataframe نشانه با داده Pytesseract بپیوندید
Bounding Box و برچسب گذاری موجودیت های پیش بینی شده
اطلاعات BIO را ترکیب کنید
جعبه مرزی
عملکرد تجزیه
تست
عنوان را تجزیه کنید
عملکرد پیشبینیها
خط لوله پیش بینی نهایی
بهبود عملکرد مدل:
ایده هایی برای بهبود دقت مدل
چارچوب مدل نسخه 2: پیش پردازش داده
مدل قطار نسخه 2
پیشبینیها را از مدل دریافت کنید
اسکنر اسناد:
منابع را دانلود کنید
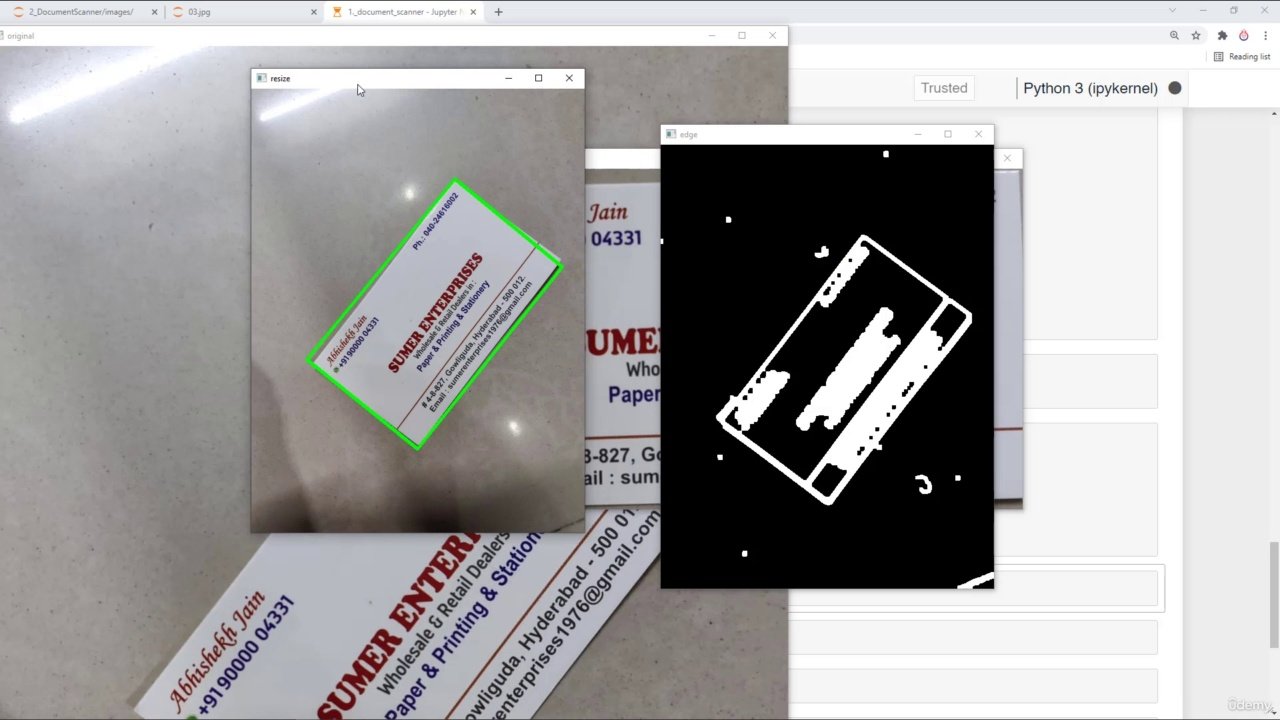
اسکنر اسناد در OpenCV چیست و چرا؟
تنظیم و خواندن تصویر
تغییر اندازه تصویر با نسبت تصویر یکسان
تشخیص لبه (بهبود، تاری و Canny) برای سند
گشاد کردن لبه ها با تبدیل مورفولوژیکی
شمارهای چهار نقطه را بیابید (محل سند را شناسایی کنید)
تبدیل Wrap را اعمال کنید و فقط سند را برش دهید
عملکرد اسکنر سند: قرار دادن همه در کنار هم
رنگ جادویی به تصویر
پیشبینیهای NER را ادغام کنید
برنامه وب اسکنر اسناد:
چه چیزی را توسعه خواهید داد؟
برنامه وب را دانلود کنید
راه اندازی پروژه برنامه وب
کد VS را نصب کنید
Flask را نصب کنید
اولین برنامه فلاسک
فایل HTML را با سرور Flask اجرا کنید
مراحل طراحی برنامه وب ما
مرحله 1: صفحه طراحی: نوار پیمایش را در HTML ایجاد کنید
مرحله 1: ایجاد صفحه درباره
مرحله 2: برای آپلود تصویر یا فایل در HTML فرم HTML ایجاد کنید
مرحله 3: نحوه پیش بینی مختصات سند با پایتون در فلاسک
مرحله 2: تصویر پشتیبان را آپلود و ذخیره کنید: settings.py را ایجاد کنید
مرحله 2: آپلود و ذخیره تصویر Backend: ذخیره تصویر از فرم HTML
مرحله 3: اسکن سند
مختصات سند را با استفاده از جاوا اسکریپت تنظیم کنید
سند را بپیچید و برش دهید و تصویر را ذخیره کنید
پیشبینیها را دریافت کنید
صفحه پیشبینیهای طراحی
نمایش نتایج در جدول
نهایی
ضمیمه:
محدودیت های Pytesseract
پاداش:
سخنرانی پاداش: مراحل بعدی
Intelligently Extract Text & Data from Document with OCR NER
در این روش نیاز به افزودن محصول به سبد خرید و تکمیل اطلاعات نیست و شما پس از وارد کردن ایمیل خود و طی کردن مراحل پرداخت لینک های دریافت محصولات را در ایمیل خود دریافت خواهید کرد.


اطلاع رسانی حذف دوره های قدیمی و تخفیفات نوروزی مشاهده









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}